Chapter 3 G-methods and Marginal Effects
3.1 Inverse probability weighting
For our illustration of IPW and g-computation, we simulate some simple confounded data.
set.seed(1747)
n <- 1e4
bZ <- 2
bX <- 2
Z <- rnorm(n, 0, 0.5)
X <- rbinom(n, 1, plogis(0.5 + Z*bZ))
Y <- rnorm(n, 10 + X*bX + Z*bZ)
d <- data.frame(Y=Y, X=X, Z=Z)For IPW, we first fit a logistic regression model of the probability of receiving treatment.
We then predict for each individual their probability of receiving treatment.
Lastly, we inverse those probabilities and use them as weights in a model – a so-called ‘marginal structural model’ – that regresses Y on X.
We then compare the treatment (solid lines) and control (dashed lines) groups before (i.e., in the observed sample) and after weighting (i.e., the IPW ‘pseudo-population’).
# IPW with unstabilized weights
library(ggplot2)
library(patchwork)
p1 <- ggplot() +
# X = 1 (sample)
geom_density(data = subset(d, X == 1),
aes(x = pX), size = 1) +
# X = 0 (sample)
geom_density(data = subset(d, X == 0),
aes(x = pX), linetype = "dashed", size = 1) +
theme_classic() +
theme(
axis.text.y = element_blank(),
axis.ticks.y = element_blank(),
axis.title.y = element_blank(),
axis.line.y = element_blank()) +
xlim(c(0,1)) + xlab("Probability of treatment") +
ggtitle("Before IP weighting")
p2 <- ggplot() +
# X = 1 (pseudo-population)
geom_density(data = subset(d, X == 1),
aes(x = pX, weight = w), size = 1) +
# X = 0 (pseudo-population)
geom_density(data = subset(d, X == 0),
aes(x = pX, weight = w), linetype = "dashed", size = 1) +
theme_classic() +
theme(
axis.text.y = element_blank(),
axis.ticks.y = element_blank(),
axis.title.y = element_blank(),
axis.line.y = element_blank()) +
xlim(c(0,1)) + xlab("Probability of treatment") +
ggtitle("After IP weighting")
(p1 + p2)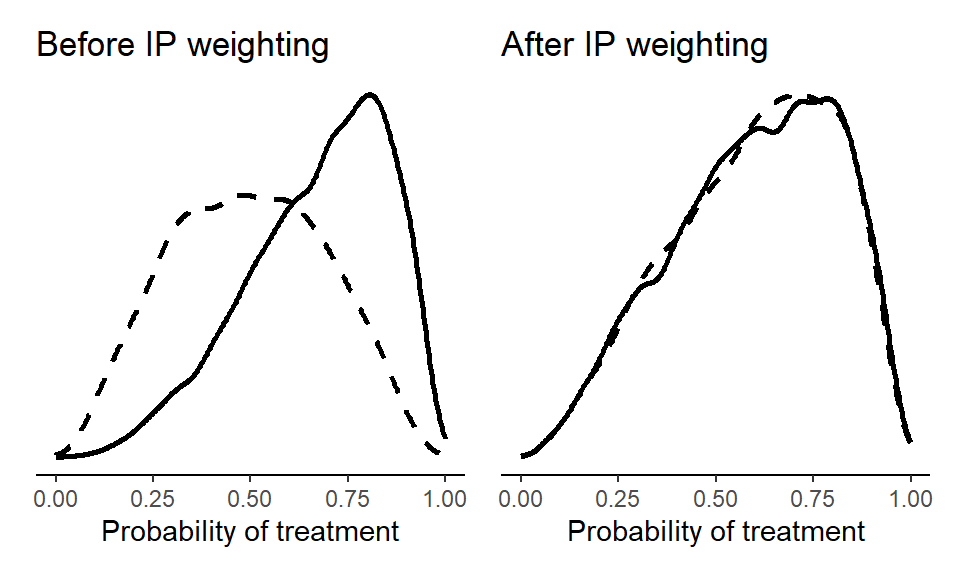
The above approach showcases IPW with so-called ‘unstabilized’ weights. But stabilizing the IP weights are often recommended. Stabilized weights uses an unconditional model for the treatment probability instead of 1 as the numerator in the IPW formula. Let’s visualize this wit the stabilized weights plotted with a dashed curve. We see that the stabilized weights are much less extreme.
# IPW with stabilized weights
pn <- glm(X ~ 1, data = d)
d$pnX <- predict(pn, type = "response")
d$sw <- with(d, ifelse(X==1, pnX/pX, (1-pnX)/(1-pX)))
p3 <- ggplot() +
geom_density(data = d,
aes(x = w), size = 1) +
geom_density(data = d,
aes(x = sw), linetype = "dashed", size = 1) +
theme_classic() +
theme_classic() +
theme(
axis.text.y = element_blank(),
axis.ticks.y = element_blank(),
axis.title.y = element_blank(),
axis.line.y = element_blank()) +
xlab("IP weight") +
coord_cartesian(xlim = c(0,10)) +
labs(title = "Unstabilized and stabilized weights")
p3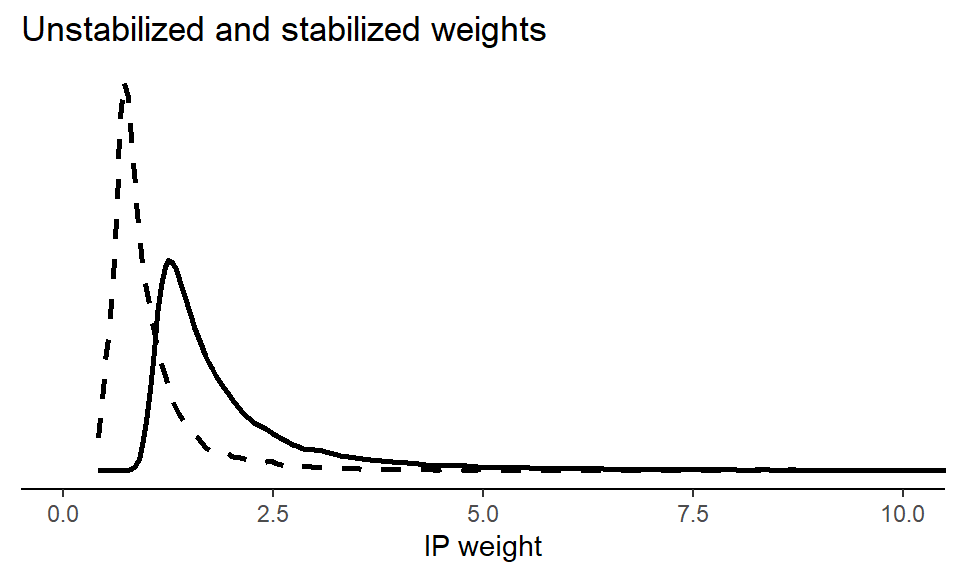
3.1.1 Bootstrapping
Here’s a basic bootstrapping approach for IPW. We use only 100 bootstrap samples, but in practice we’d often want (many) more.
# Load necessary libraries
library(boot)
# Number of bootstrap samples
n_bootstrap <- 100
# Function to perform the analysis on a bootstrapped sample
bootstrap_analysis <- function(data, indices) {
# Resample the data
d <- data[indices, ]
# Fit the treatment model using logistic regression
treatment_model <- glm(X ~ Z, data = d, family = "binomial")
# Calculate predicted probabilities
d$pX <- predict(treatment_model, type = "response")
# Calculate weights
d$w <- with(d, ifelse(X == 1, 1 / pX, 1 / (1 - pX)))
# Fit the weighted linear regression model
weighted_model <- lm(Y ~ X, data = d, weights = w)
# Return the coefficient of X
return(coef(weighted_model)["X"])
}
# Perform bootstrapping
bootstrap_results <- boot(data = d,
statistic = bootstrap_analysis,
R = n_bootstrap)
# Summarize the bootstrap results
bootstrap_summary <- boot.ci(bootstrap_results, type = "norm")
# Print the results
print(bootstrap_summary)## BOOTSTRAP CONFIDENCE INTERVAL CALCULATIONS
## Based on 100 bootstrap replicates
##
## CALL :
## boot.ci(boot.out = bootstrap_results, type = "norm")
##
## Intervals :
## Level Normal
## 95% ( 1.946, 2.057 )
## Calculations and Intervals on Original Scale3.2 G-computation
Here, we show a basic g-computation workflow…
model <- lm(Y ~ X + Z, data = d)
d$EX1 <- predict(model,
newdata = transform(d, X = 1))
d$EX0 <- predict(model,
newdata = transform(d, X = 0))
with(d, mean(EX1)-mean(EX0))… And code to produce the table showing both observed and predicted values, some of which are counter-factual.
## % latex table generated in R 4.4.1 by xtable 1.8-4 package
## % Sun Aug 24 22:05:56 2025
## \begin{table}[ht]
## \centering
## \begin{tabular}{rrrrrr}
## \hline
## & Y & X & Z & EX1 & EX0 \\
## \hline
## 1 & 15.3 & 1 & 0.6 & 13.2 & 11.2 \\
## 2 & 11.1 & 0 & 0.1 & 12.2 & 10.2 \\
## 3 & 10.6 & 1 & -0.1 & 11.7 & 9.7 \\
## 4 & 12.9 & 1 & 0.7 & 13.4 & 11.3 \\
## 5 & 11.0 & 1 & -0.5 & 10.9 & 8.9 \\
## 6 & 9.4 & 0 & 0.5 & 12.9 & 10.9 \\
## \hline
## \end{tabular}
## \end{table}3.2.1 Bootstrapping
Next, we show a basic bootstrapped g-computation implementation, again using only 100 bootstrap samples to ease the computational burden of the example.
# Number of bootstrap samples
n_bootstrap <- 100
# Define the function to perform the analysis on a bootstrapped sample
bootstrap_analysis <- function(data, indices) {
# Resample the data
d <- data[indices, ]
# Fit the linear regression model
model <- lm(Y ~ X + Z, data = d)
# Calculate predicted values for X = 1 and X = 0
d$EX1 <- predict(model, newdata = transform(d, X = 1))
d$EX0 <- predict(model, newdata = transform(d, X = 0))
# Compute the difference in means
ate <- with(d, mean(EX1) - mean(EX0))
return(ate)
}
# Perform bootstrapping
bootstrap_results <- boot(data = d,
statistic = bootstrap_analysis,
R = n_bootstrap)
# Summarize the bootstrap results
bootstrap_summary <- boot.ci(bootstrap_results, type = c("norm"))
# Print the results
print(bootstrap_summary)## BOOTSTRAP CONFIDENCE INTERVAL CALCULATIONS
## Based on 100 bootstrap replicates
##
## CALL :
## boot.ci(boot.out = bootstrap_results, type = c("norm"))
##
## Intervals :
## Level Normal
## 95% ( 1.962, 2.050 )
## Calculations and Intervals on Original Scale3.2.2 Bayesian g-computation
Lastly, we show a Bayesian g-computation workflow using the R package brms (Bürkner 2017, 2018, 2021), which requires RStan (Stan Development Team, n.d.), for model fitting and tidybayes for post-processing (Kay 2023).
# Fit Bayesian regression
bmodel <- brm(Y ~ X + Z,
data = d,
cores = 4, seed = 1,
file = "fits/bmodel.rds")# Calculate predicted values for X = 1 and X = 0
bEX1 <- add_epred_draws(object = bmodel,
newdata = transform(d, X = 1))
bEX0 <- add_epred_draws(object = bmodel,
newdata = transform(d, X = 0))The key thing to note when working with Bayesian model fits is that we need to calculate our quantity of interest (here, the ATE) within each posterior draw.
# Compute the difference in means
ate <- data.frame(EX1 = bEX1$.epred,
EX0 = bEX0$.epred,
draw = bEX0$.draw) |>
# For each posterior draw...
group_by(draw) |>
# ... Calculate ATE
summarise(ate = mean(EX1 - EX0))We can summarize the posterior ATE by its mean and highest posterior density interval.
## y ymin ymax .width .point .interval
## 1 2.009257 1.964355 2.051421 0.95 mean hdiAn alternative approach – when we have a fitted model, Bayesian or otherwise – is via the versatile and very well documented marginaleffects package (Arel-Bundock, Greifer, and Heiss Forthcoming).
##
## Estimate 2.5 % 97.5 %
## 2.01 1.96 2.05
##
## Term: X
## Type: response
## Comparison: mean(1) - mean(0)
## Columns: term, contrast, estimate, conf.low, conf.high, predicted_lo, predicted_hi, predicted, tmp_idx3.3 Session info
## R version 4.4.1 (2024-06-14 ucrt)
## Platform: x86_64-w64-mingw32/x64
## Running under: Windows 10 x64 (build 19045)
##
## Matrix products: default
##
##
## locale:
## [1] LC_COLLATE=Danish_Denmark.utf8 LC_CTYPE=Danish_Denmark.utf8
## [3] LC_MONETARY=Danish_Denmark.utf8 LC_NUMERIC=C
## [5] LC_TIME=Danish_Denmark.utf8
##
## time zone: Europe/Copenhagen
## tzcode source: internal
##
## attached base packages:
## [1] stats graphics grDevices utils datasets methods base
##
## other attached packages:
## [1] marginaleffects_0.23.0 dplyr_1.1.4 tidybayes_3.0.6
## [4] brms_2.21.0 Rcpp_1.0.12 sandwich_3.1-1
## [7] boot_1.3-30 patchwork_1.3.0 ggplot2_3.5.1
##
## loaded via a namespace (and not attached):
## [1] gtable_0.3.5 tensorA_0.36.2.1 xfun_0.48
## [4] bslib_0.7.0 QuickJSR_1.2.2 insight_0.20.5
## [7] collapse_2.0.16 inline_0.3.19 lattice_0.22-6
## [10] vctrs_0.6.5 tools_4.4.1 generics_0.1.4
## [13] stats4_4.4.1 parallel_4.4.1 tibble_3.2.1
## [16] highr_0.11 pkgconfig_2.0.3 Matrix_1.7-0
## [19] data.table_1.15.4 checkmate_2.3.1 distributional_0.5.0
## [22] RcppParallel_5.1.7 lifecycle_1.0.4 compiler_4.4.1
## [25] farver_2.1.2 stringr_1.5.1 Brobdingnag_1.2-9
## [28] munsell_0.5.1 codetools_0.2-20 htmltools_0.5.8.1
## [31] sass_0.4.9 bayesplot_1.11.1 yaml_2.3.8
## [34] tidyr_1.3.1 pillar_1.10.2 jquerylib_0.1.4
## [37] arrayhelpers_1.1-0 cachem_1.1.0 StanHeaders_2.35.0.9000
## [40] bridgesampling_1.1-2 abind_1.4-8 nlme_3.1-164
## [43] posterior_1.6.1 rstan_2.35.0.9000 svUnit_1.0.6
## [46] tidyselect_1.2.1 digest_0.6.35 mvtnorm_1.2-5
## [49] stringi_1.8.4 purrr_1.0.2 bookdown_0.41
## [52] labeling_0.4.3 splines_4.4.1 fastmap_1.2.0
## [55] grid_4.4.1 colorspace_2.1-0 cli_3.6.2
## [58] magrittr_2.0.3 loo_2.8.0 pkgbuild_1.4.4
## [61] withr_3.0.2 scales_1.3.0 backports_1.5.0
## [64] estimability_1.5.1 rmarkdown_2.27 matrixStats_1.3.0
## [67] emmeans_1.10.5 gridExtra_2.3 zoo_1.8-12
## [70] coda_0.19-4.1 evaluate_1.0.4 knitr_1.47
## [73] ggdist_3.3.2 mgcv_1.9-1 rstantools_2.4.0
## [76] rlang_1.1.4 xtable_1.8-4 glue_1.7.0
## [79] rstudioapi_0.16.0 jsonlite_1.8.8 R6_2.5.1References
marginaleffects in R and Python.” Journal of Statistical Software, Forthcoming. https://marginaleffects.com.