Chapter 6 More Missing Data
6.1 Simple mean imputation vs. multiple imputation
Here we illustrate simple mean imputation.
d <- read.csv("data/cohen2015miss.csv")
d$age <- scale(d$age) |> as.numeric()
d_mimp <- d
d_mimp$age <- with(d_mimp,
ifelse(is.na(age),
mean(age, na.rm = T),
age))
lm(act ~ subsidy + age, data = d_mimp) |> summary()##
## Call:
## lm(formula = act ~ subsidy + age, data = d_mimp)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.4774 -0.3866 -0.2396 0.5566 0.9431
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 0.19126 0.03555 5.380 1.05e-07 ***
## subsidy 0.19535 0.04151 4.706 3.11e-06 ***
## age -0.06592 0.01892 -3.485 0.000527 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.4608 on 628 degrees of freedom
## (34 observations deleted due to missingness)
## Multiple R-squared: 0.05275, Adjusted R-squared: 0.04973
## F-statistic: 17.49 on 2 and 628 DF, p-value: 4.074e-08We can compare with a complete-case analysis…
##
## Call:
## lm(formula = act ~ subsidy + age, data = d)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.4908 -0.3978 -0.2439 0.5472 0.9378
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 0.19579 0.03679 5.321 1.46e-07 ***
## subsidy 0.20467 0.04291 4.769 2.33e-06 ***
## age -0.06558 0.01905 -3.443 0.000615 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.464 on 598 degrees of freedom
## (64 observations deleted due to missingness)
## Multiple R-squared: 0.05574, Adjusted R-squared: 0.05258
## F-statistic: 17.65 on 2 and 598 DF, p-value: 3.565e-08… As well as multiple imputation.
## term estimate std.error statistic df p.value
## 1 (Intercept) 0.18965550 0.03496624 5.423960 550.9040 8.739647e-08
## 2 subsidy 0.19910361 0.04072650 4.888798 580.3649 1.314949e-06
## 3 age -0.06753163 0.01892160 -3.569022 153.9652 4.781627e-04In all cases, the point estimate for both the intercept and effect of subsidy is around 0.20.
6.2 “Combine then predict” or “predict then combine”?
In the main text we say that we have a choice to make when working with a model fitted on multiply imputed data: Do we apply Rubin’s pooling rules on the model coefficients or on model predictions? We can refer to these different approaches as “combine then predict” and “predict then combine,” respectively, following Miles (2016).
Since different R packages implement post-processing of multiply imputed model fits differently, we show a basic implementations here with two popular R packages. What the packages have in common is that they allow us to conveniently work with the mice object as we would any other model fit. Let’s proceed with the malaria subsidy data and imagine we want an average treatment effect of the subsidy treatment of ACT uptake marginal of age using g-computation.
6.2.1 marginaleffects
The marginaleffects package (Arel-Bundock, Greifer, and Heiss Forthcoming) implements “predict then combine”; that is, it obtains model predictions for each of the m data sets and then apply Rubin’s rules to the predictions to pool them. G-computation with multiply imputed datasets is very straightforward to implement.
##
## Estimate Std. Error t Pr(>|t|) S 2.5 % 97.5 % Df
## 0.199 0.0407 4.89 <0.001 19.9 0.119 0.279 5965
##
## Term: subsidy
## Type: response
## Comparison: mean(1) - mean(0)
## Columns: term, contrast, estimate, std.error, s.value, predicted_lo, predicted_hi, predicted, df, statistic, p.value, conf.low, conf.high6.2.2 emmeans
On the other hand, the emmeans package (R. V. Lenth 2024) implements “combine then predict”; that is, it applies Rubin’s rules to the model coefficients to pool them and only then obtain model predictions. A basic g-computation implementation with multiply imputed datasets could like this using emmeans.
## contrast estimate SE df lower.CL upper.CL
## subsidy1 - subsidy0 0.199 0.0407 580 0.119 0.279
##
## Confidence level used: 0.95We see that results are identical to those obtained with marginaleffects.
6.2.3 Comparison
But let’s try to see when the two different approaches give different results, such as for non-linear models. Instead of a linear model on the imputed datasets, we instead use a non-linear model in the form of a logistic regression. We do this by calling glm() instead of lm() and setting family = "binomial".
Then, we apply our two approaches. The marginaleffects implementation is identical to above even though the model fit is now a logistic regression.
##
## Estimate Std. Error t Pr(>|t|) S 2.5 % 97.5 % Df
## 0.201 0.0369 5.44 <0.001 24.1 0.128 0.273 3541
##
## Term: subsidy
## Type: response
## Comparison: mean(1) - mean(0)
## Columns: term, contrast, estimate, std.error, s.value, predicted_lo, predicted_hi, predicted, df, statistic, p.value, conf.low, conf.highFor the emmeans approach, to get predictions on the probability scale, we can wrap the ref_grid() function in regrid() and set type = "response". We see that results are very similar but not identical.
emmeans(specs = "subsidy",
regrid(ref_grid(fit_binom),
type = "response")) |>
contrast("revpairwise") |>
confint()## contrast estimate SE df lower.CL upper.CL
## subsidy1 - subsidy0 0.203 0.037 1566 0.13 0.275
##
## Confidence level used: 0.956.3 Bayesian imputation
In the book, we also mentioned an alternative imputation approach, namely Bayesian imputation. Using the brms package (Bürkner 2017, 2018, 2021), we’ll show a very basic implementation. The syntax should seem somewhat familiar, as brms uses common R regression syntax.
First, we define the model formula. At its core, it’s similar to the lm() formula above, except for a few complications. The formula object holds two main components, each wrapped by bf(). In the first part, we indicate the covariate we want to impute – in the case, age – with the mi() wrapper. The second part specifies a model for the variable we want to impute. Finally, we feed that formula to brm() along with the data. We then set the cores to 4 for speedier sampling and a seed for numeric reproducibility. We strongly recommend McElreath (and Kurz’ translation) (Kurz 2023; McElreath 2020) for more details and a general introduction to Bayesian inference more generally.
# Define model formula
formula <- bf(act ~ subsidy + mi(age)) +
bf(age | mi() ~ 1)
# Fit model to data
bfit <- brm(formula,
data = d,
cores = 4, seed = 2020,
file = "fits/bfit.rds")We can get a summary of the Bayesian model by calling summary()
## Family: MV(gaussian, gaussian)
## Links: mu = identity; sigma = identity
## mu = identity; sigma = identity
## Formula: act ~ subsidy + mi(age)
## age | mi() ~ 1
## Data: d (Number of observations: 631)
## Draws: 4 chains, each with iter = 2000; warmup = 1000; thin = 1;
## total post-warmup draws = 4000
##
## Regression Coefficients:
## Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
## act_Intercept 0.19 0.04 0.12 0.26 1.00 8466 2986
## age_Intercept -0.02 0.04 -0.10 0.06 1.00 6946 3032
## act_subsidy 0.20 0.04 0.12 0.28 1.00 7634 2840
## act_miage -0.06 0.02 -0.10 -0.03 1.00 9493 2986
##
## Further Distributional Parameters:
## Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
## sigma_act 0.46 0.01 0.44 0.49 1.00 8351 3073
## sigma_age 1.00 0.03 0.94 1.06 1.00 6670 2543
##
## Draws were sampled using sampling(NUTS). For each parameter, Bulk_ESS
## and Tail_ESS are effective sample size measures, and Rhat is the potential
## scale reduction factor on split chains (at convergence, Rhat = 1).The coefficient act_subsidy corresponds to the subsidy coefficient in the lm() and glm() calls above. We see that the coefficients are very similar to the models above, except now we also have coefficients for the model predicting age (the age_ parameters).
Now, there are many ways to extend this model, which are outside the scope of this companion website, for instance using more informative prior settings, constraining imputed values to be within realistic ranges, include covariates in the sub-model predicting missing age values, or use a different likelihood for act that respects its binary nature (e.g., a logistic regression model).
We can also inspect the distribution of imputed values. For instance, we can plot 20 draws from the distribution of the imputed age variable (light blue curves) against the observed distribution of age in the sample (dark blue curve)…
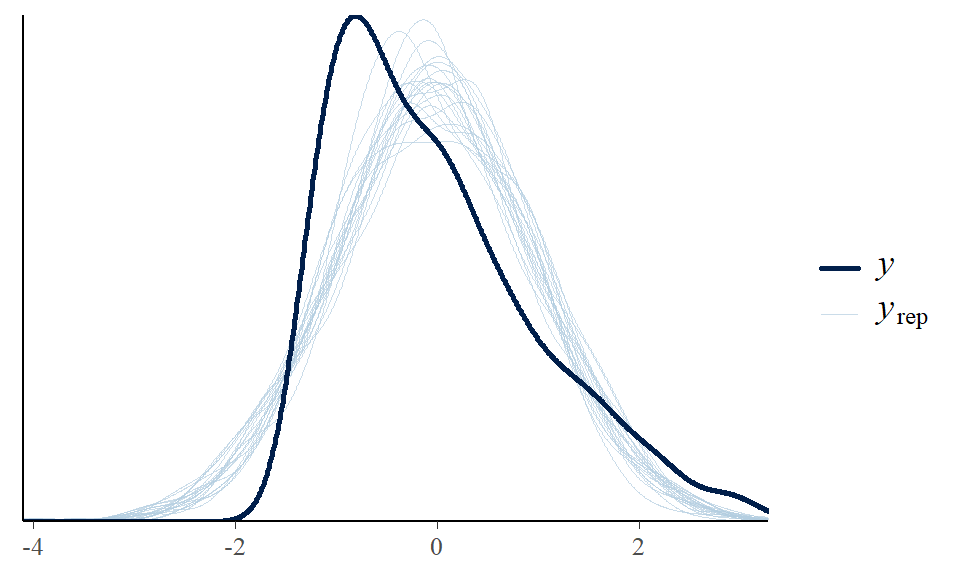
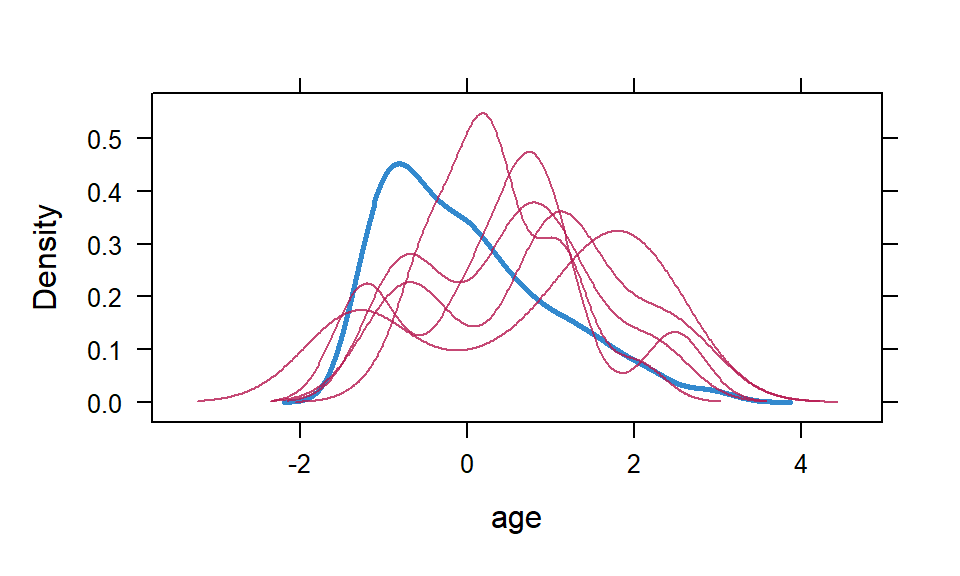
… Which is somewhat similar to this plot of imputed data sets (red curves) against the observed (blue curve) from the mice implementation shown in the text.
Now, we can post-process the Bayesian model fit exactly as shown in Chapters 3 and 5 using the tidybayes-based workflow (Kay 2023). Or, we can use marginaleffects just as shown for the mice object above, except we need to specify that it’s the model predicting ACT uptake that we want to apply g-computation to; this is what resp = "act" does.
##
## Estimate 2.5 % 97.5 %
## 0.195 0.116 0.276
##
## Term: subsidy
## Type: response
## Comparison: mean(1) - mean(0)
## Columns: term, contrast, estimate, conf.low, conf.high, predicted_lo, predicted_hi, predicted, tmp_idx6.4 Session info
## R version 4.4.1 (2024-06-14 ucrt)
## Platform: x86_64-w64-mingw32/x64
## Running under: Windows 10 x64 (build 19045)
##
## Matrix products: default
##
##
## locale:
## [1] LC_COLLATE=Danish_Denmark.utf8 LC_CTYPE=Danish_Denmark.utf8
## [3] LC_MONETARY=Danish_Denmark.utf8 LC_NUMERIC=C
## [5] LC_TIME=Danish_Denmark.utf8
##
## time zone: Europe/Copenhagen
## tzcode source: internal
##
## attached base packages:
## [1] stats graphics grDevices utils datasets methods base
##
## other attached packages:
## [1] emmeans_1.10.5 mice_3.16.0 haven_2.5.4
## [4] cobalt_4.5.5 causaldata_0.1.4 marginaleffects_0.23.0
## [7] dplyr_1.1.4 tidybayes_3.0.6 brms_2.21.0
## [10] Rcpp_1.0.12 sandwich_3.1-1 boot_1.3-30
## [13] patchwork_1.3.0 ggplot2_3.5.1
##
## loaded via a namespace (and not attached):
## [1] gridExtra_2.3 inline_0.3.19 rlang_1.1.4
## [4] magrittr_2.0.3 matrixStats_1.3.0 compiler_4.4.1
## [7] mgcv_1.9-1 loo_2.8.0 vctrs_0.6.5
## [10] reshape2_1.4.4 stringr_1.5.1 pkgconfig_2.0.3
## [13] shape_1.4.6.1 arrayhelpers_1.1-0 crayon_1.5.3
## [16] fastmap_1.2.0 backports_1.5.0 labeling_0.4.3
## [19] rmarkdown_2.27 tzdb_0.4.0 nloptr_2.1.1
## [22] purrr_1.0.2 xfun_0.48 glmnet_4.1-8
## [25] jomo_2.7-6 cachem_1.1.0 jsonlite_1.8.8
## [28] collapse_2.0.16 highr_0.11 pan_1.9
## [31] chk_0.9.2 broom_1.0.6 parallel_4.4.1
## [34] R6_2.5.1 bslib_0.7.0 stringi_1.8.4
## [37] StanHeaders_2.35.0.9000 rpart_4.1.23 jquerylib_0.1.4
## [40] estimability_1.5.1 bookdown_0.41 rstan_2.35.0.9000
## [43] iterators_1.0.14 knitr_1.47 zoo_1.8-12
## [46] readr_2.1.5 bayesplot_1.11.1 nnet_7.3-19
## [49] Matrix_1.7-0 splines_4.4.1 tidyselect_1.2.1
## [52] rstudioapi_0.16.0 abind_1.4-8 yaml_2.3.8
## [55] codetools_0.2-20 pkgbuild_1.4.4 lattice_0.22-6
## [58] tibble_3.2.1 plyr_1.8.9 withr_3.0.2
## [61] bridgesampling_1.1-2 posterior_1.6.1 coda_0.19-4.1
## [64] evaluate_1.0.4 survival_3.6-4 RcppParallel_5.1.7
## [67] ggdist_3.3.2 pillar_1.10.2 tensorA_0.36.2.1
## [70] checkmate_2.3.1 foreach_1.5.2 stats4_4.4.1
## [73] insight_0.20.5 distributional_0.5.0 generics_0.1.4
## [76] hms_1.1.3 rstantools_2.4.0 munsell_0.5.1
## [79] scales_1.3.0 minqa_1.2.7 xtable_1.8-4
## [82] glue_1.7.0 tools_4.4.1 data.table_1.15.4
## [85] lme4_1.1-35.4 forcats_1.0.0 mvtnorm_1.2-5
## [88] grid_4.4.1 tidyr_1.3.1 QuickJSR_1.2.2
## [91] colorspace_2.1-0 nlme_3.1-164 cli_3.6.2
## [94] svUnit_1.0.6 Brobdingnag_1.2-9 gtable_0.3.5
## [97] sass_0.4.9 digest_0.6.35 farver_2.1.2
## [100] htmltools_0.5.8.1 lifecycle_1.0.4 mitml_0.4-5
## [103] MASS_7.3-60.2References
marginaleffects in R and Python.” Journal of Statistical Software, Forthcoming. https://marginaleffects.com.